문자인식(OCR): 종이문서 디지털화에서 모바일 터치리더(Touch Reader)까지 ... ![]() 문자인식에 대해서...
문자인식에 대해서... ![]()
지금까지 여러 번 문자인식(OCR)의 제품들이나 응용분야에 대해 얘기하고 있지만, 오늘은 약간 개론적인 내용으로 정리하면서 글을 쓰려 합니다. 뭐 다 이전에 강의나 세미나 등에서 했던 얘기나 자료들을 기반으로 가감하면서 쓰는 것이긴 합니다. 사실은 문자인식의 응용분야에 대해서는 모두 다 열거할 수는 없을 듯 합니다. 그래서 제목을 "문자인식(OCR): 종이문서 디지털화에서 모바일 터치리더(Touch Reader)까지..."라고 했습니다. 비즈니스 환경에서 최초 문자인식 응용분야의 대부분이었던 종이문서의 디지털화에서 최근 모바일 기기가 확산되면서 활발해지고 있는 모바일 문자인식 분야까지 살펴보는 의미에서 말입니다.
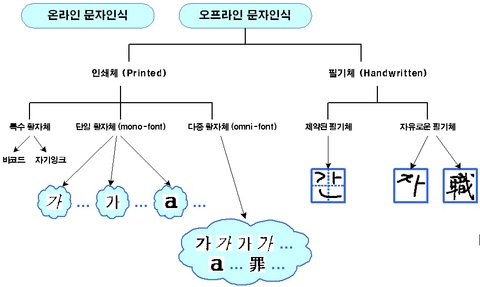
문자인식은 온라인 문자인식(online handwriting recognition)이냐 오프라인 문자인식(offline character recogntion)이냐로 분류하기도 하고, 또 오프라인 문자인식은 인쇄체(printed) 문자인식이냐 필기체(handwritten) 문자인식이냐로 분류하기도 하고, 언어별로 분류하기도 하고, 그 외에도 다양한 환경, 조건에 따라 분류하기도 합니다. 어디 책에선가 인용한 것인데...한 가지더 문자인식의 처리 과정도 한 번 보시죠. 역시 어디선가 인용했습니다. 또 이렇게 되는 것이 아니기 때문에 " 아 이렇구나" 하는 정도로 봐 주시면 좋겠습니다.
<문자인식 분류, 출처 미상(?)>
<문자인식 처리과정, 출처 미상(?)>
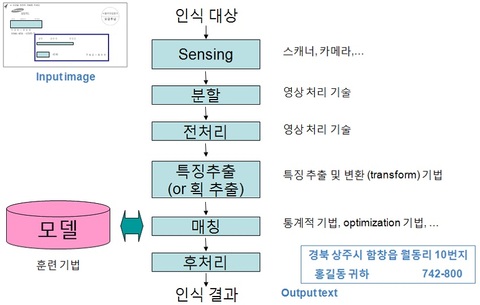
이전 글에서 말씀 드렸습니다만, 이런 문자인식 처리과정에서 입력되는 이미지가 스캐너에서 생성된 것이냐 카메라를 통해 생성된 것이냐, 문서 이미지가 정형성이 있느냐 없느냐, 문자 개별적인 특징은 어떻느냐, 어떤 언어인 것이냐, 등등...... 에 따라 각 단계의 중요도나 어려움이 다 다릅니다. 한 마디로 다 같은 문자인식이 아니라는 거 꼭 기억해 주세요...
종이문서의 디지털화(digitalization)는 "전자도서관 또는 디지털라이브러리(digital library)"의 개념과 무관하지 않습니다. 종이문서의 재생산이든, 종이문서의 이미지화 과정에서 검색이 가능한(searchable) 매체의 생산이든, 이 시점에 무엇보다 연구나 상용화에 대한 시도가 많았기 때문입니다. 디지털화 대상은 주로 서적, 잡지, 논문이나 신문 등 어느 정도 정형성이 있는 문서에 대한 처리 요건이 대부분이었습니다. 여기에서는 문자인식보다는 문서구조분석(Document structure analysis)에 대한 시도들이 더 많았던 것 같습니다.
<종이문서 디지털화, 문서구조분석 예시>
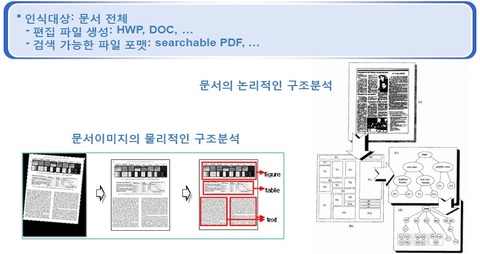
1990년도 대부분은 전자도서관, 디지털화, OCR, 뭐 이런 부분들이 문자인식 연구의 주테마이기도 했고, 국가기관 대부분, 국공립도서관, 대학도서관 등 대부분은 이것을 위한 예산을 많이 집행할 시점이었습니다. 나름 성공도 했지만, 그때 주된 연구기관이나 기업들이 지금까지 명맥을 유지하지 못하는 것을 보면 꼭 성공적이라고 할 수도 없습니다.
이제 서서히 2000년대 초반으로 가면서 비즈니스 업무환경의 전반적인 종이문서 위주의 업무프로세스를 혁신하고자 하는 시도들이 금융권을 중심으로 일어납니다. 이제 종이문서도 일반적인 서적 위주의 문서에서 서식(form)이라는 것으로 처리 대상이 변화합니다. 서식문서로부터 특정 영역의 정보를 자동으로 추출, 인식하여 DB화를 해줌으로써, 수작업 입력으로 처리하던 비용과 시간 단축이라는 효과를 내기 시작하면서 매우 효율적인 응용분야로 각광을 맏기 시작합니다.
<서식문서의 특정 영역을 문자인식하고 데이터베이스화 하는 예시 1>

<서식문서의 특정 영역을 문자인식하고 데이터베이스화 하는 예시 2>

이러한 업무 혁신 프로젝트는 금융권 BPR(Business Process Reengineering)이라는 사업명으로 지금까지 금융권 및 공공기관에서도 진행 또는 확대되고 있습니다. 기존 종이문서가 이동하던 모든 프로세스가 이미지와 해당 정보들의 전송으로 바뀌면서 업무 속도뿐만 아니라 정확도 등에서 비약적인 성과를 거둔 것이죠. 뭐 복잡하게 설명할것 없이, 은행에서 대출받던 형태를 생각해 보면 간단합니다. 종이문서 시대에는 은행에서 서류의 대부분 영역을 다 작성하도 대출 신청하면 한 1주일 있다가 대출 여부, 이자율 등의 정보를 담당직원이 알려 주었죠. 이 모든 시간 소요가 종이문서의 이동과 수작업으로 처리하는 시간에 의해 초래된 것이었습니다. 지금 어떻습니까? 대출 서류의 적당 부분만 작성하면 담당직원이 오후나 내일 아침정도에 알려줍니다. 바로 모든 서류가 스캐너를 통해 이미지로, 그리고 문자인식을 통해 자동화되면서 대출 심사라는 업무가 매우 빠르게 진행되기 때문이죠.
그런데, 이것과 유사한 시점에 "국가 지식자원관리"라는 이슈가 나타납니다. 국가에서 중요하다고 고려하고 있는 사회, 과학, 역사, 문화, 교육 전반에 걸쳐 중요한 기관의 종이문서를 디지털화하는 사업들이 나타나게 됩니다. 이중에서 가장 이슈는 역사분야에 대한 국가지식정보를 디지털화해야 하는 문제였습니다. 지금까지 어떤 문자인식 기술도 접하지 못한, 아니 도전하지 않은 분야였기 때문이었죠.
<문서이미지화 및 문자인식이 처리해야 하는 역사사료 예시>

간단히 몇가지 사진을 첨부해 봤는데, 느낌이 오시나요?! 너무도 어려운 문제였지만 시도가 있었습니다. KAIST 인공지능연구실과 어떤 기업가가 의기투합을 한 것이죠. 문자인식의 역할이 기존 문서 디지털화에서와는 달랐지만, 역사사료의 디지털화를 위한 처리율과 정확도가 매우 높았기 때문에 연구가 계속되었고, 이후 중국의 칭화대학교와 일본의 동경대학교에서도 그 연구와 성과를 높이 평가하기도 했습니다.
<목판본 사료의 문자인식 적용 사례, 출처: KAIST 인공지능연구실>
<필기체 사료의 문자인식 적용 사례, 출처: KAIST 인공지능연구실>
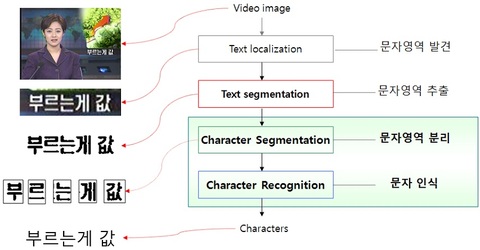
이후의 문자인식 기술은 동영상 색인(indexing)을 위한 도구로도 활용됩니다. 동영상의 장면들도 결국 연속된 이미지들의 집합이기 때문에 동영상에서 나타나는 그래픽 텍스트(graphical text)들을 자동 추출하여, 문자인식을 통해 해당 동영상의 DB화에 활용하는 것입니다. 이렇게 되면 엄청나게 많은 동영상 DB에서도 해당 자료를 잘 찾을 수 있겠죠?
<동영상 자동 색인 및 검색 분야의 문자인식 적용 예시, 출처: KAIST 인공지능연구실>
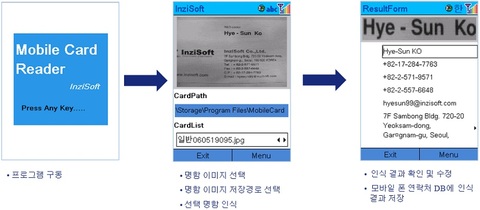
문자인식 기술은 개인화 패키지 제품으로도 상용화에 성공합니다. 무수한 명함인식 제품들이 그 예라고 할 수 있습니다. 국내외적으로 꾸준히 사업들을 유지하고 있는 제품들이 많이 있으며, 최근에는 모바일 환경으로 다양한 app들이 출시되고 있습니다. 이 부분에 대한 얘기는 나중에 따로 주제를 한 번 정해서 글을 써봐야 할 듯 합니다.
<인지소프트의 모바일 명함인식 제품 예시, 2007년도 제품으로 추정>
이제 마지막, 문자인식 기술은 최근 스마트폰 시장이 오픈되면서 모바일환경에서 다양한 기능을 수행하는 app들로 그 모습을 드러내고 있습니다. 모바일 환경에서 종이문서를 자동으로 추출하여 문자인식을 수행하는 것뿐만 아니라, 좀더 나아가 터치리더(Touch Reader)와 같이 주변에서 만나는 다양한 텍스트 정보들, 간판, 메뉴, 도로표지 등에 나타나는 텍스트들까지 처리하려고 하고 있습니다.
<간판을 인식하여 번역하고 있는 모바일 터치리더의 예시>


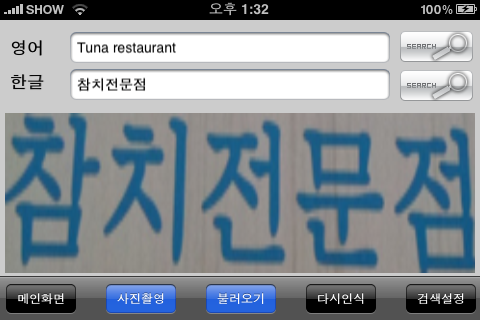
이 예시는 정형화된 폰트 스타일이지만, 기본적으로 이런 텍스트들은 정형화된 폰트(font) 스타일을 적용하기 보다는 다양한 그래픽요소를 가미하기 때문에 문자인식의 어려움이 클 것입니다. 어떻게 보면 구글(Google)에와 같이 엄청난 사진DB를 보유한 경우, 문자인식이 아닌 이미지 매칭(image matching)을 통해 처리하는 것이 더 좋을지도 모릅니다.
'█ NSCB' 카테고리의 다른 글
| 딥 러닝 기반 하이크비전 문자인식기술 세계최고 수준 입증 (0) | 2018.04.26 |
|---|---|
| 2018 제1차 창업 도약 패키지 지원 사업 (0) | 2018.04.17 |
| 2018년 창업성장기술개발사업 디딤돌창업과제 3차 시행계획 공고 (0) | 2018.04.12 |
| 갈수록 악화하는 편의점 사업환경 (0) | 2018.03.26 |
| 2018 제3차 창업성장기술개발과제 공고 (0) | 2018.03.22 |